Overlay¶
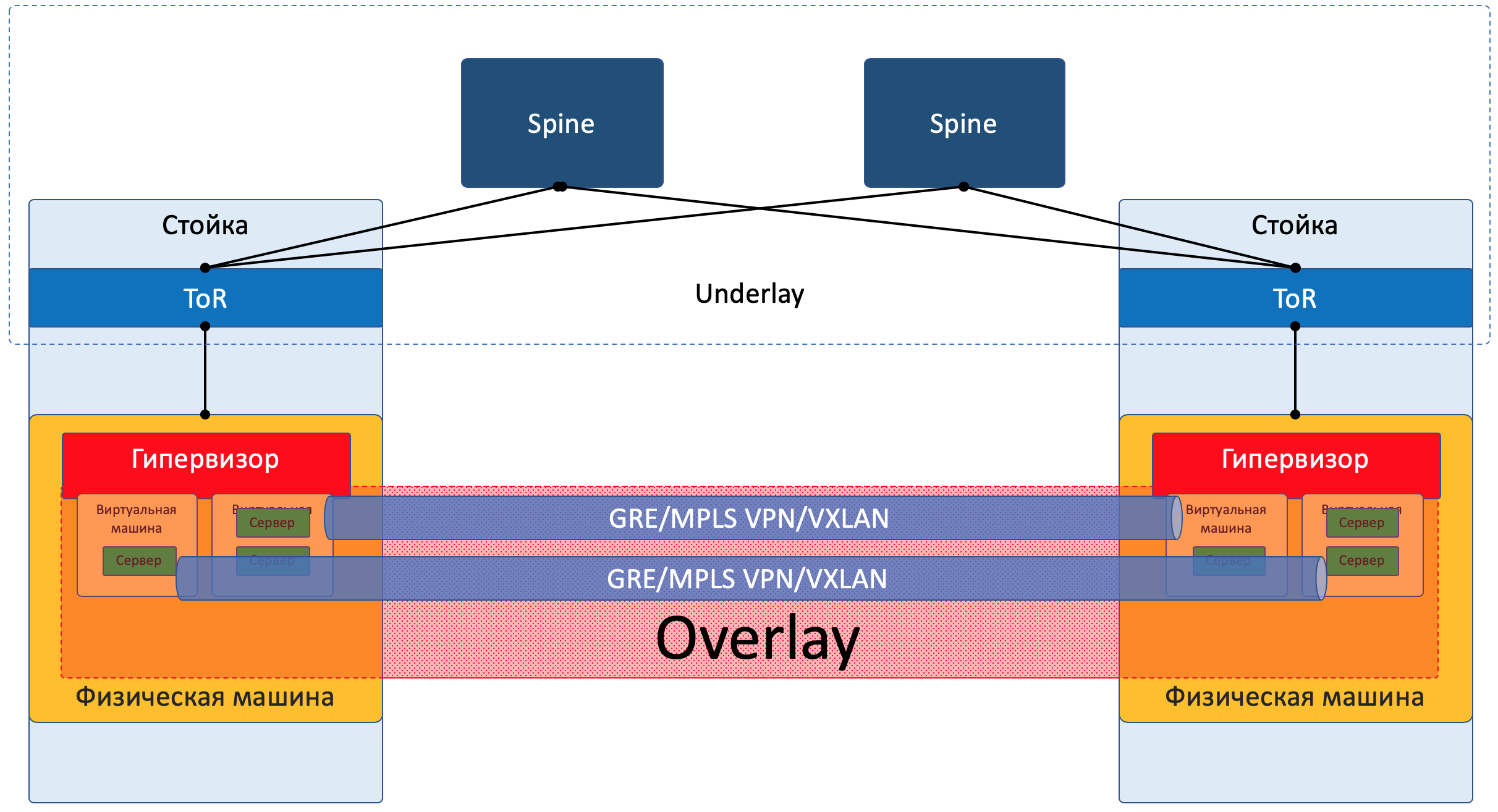
Так ВМ одного клиента (одного сервиса) могут общаться друг с другом через Overlay, даже не подозревая какой на самом деле путь проходит пакет. Overlay может быть например таким, как уже я упоминал выше:
- GRE-туннель
- VXLAN
- EVPN
- L3VPN
- GENEVE
Overlay’ная сеть обычно настраивается и поддерживается через центральный контроллер. С него конфигурация, Control Plane и Data Plane доставляются на устройства, которые занимаются маршрутизацией и инкапсуляцией клиентского трафика. Чуть ниже разберём это на примерах. Да, это SDN в чистом виде.
Существует два принципиально различающихся подхода к организации Overlay-сети:
- Overlay с ToR’a
- Overlay с хоста
Overlay с ToR’a¶
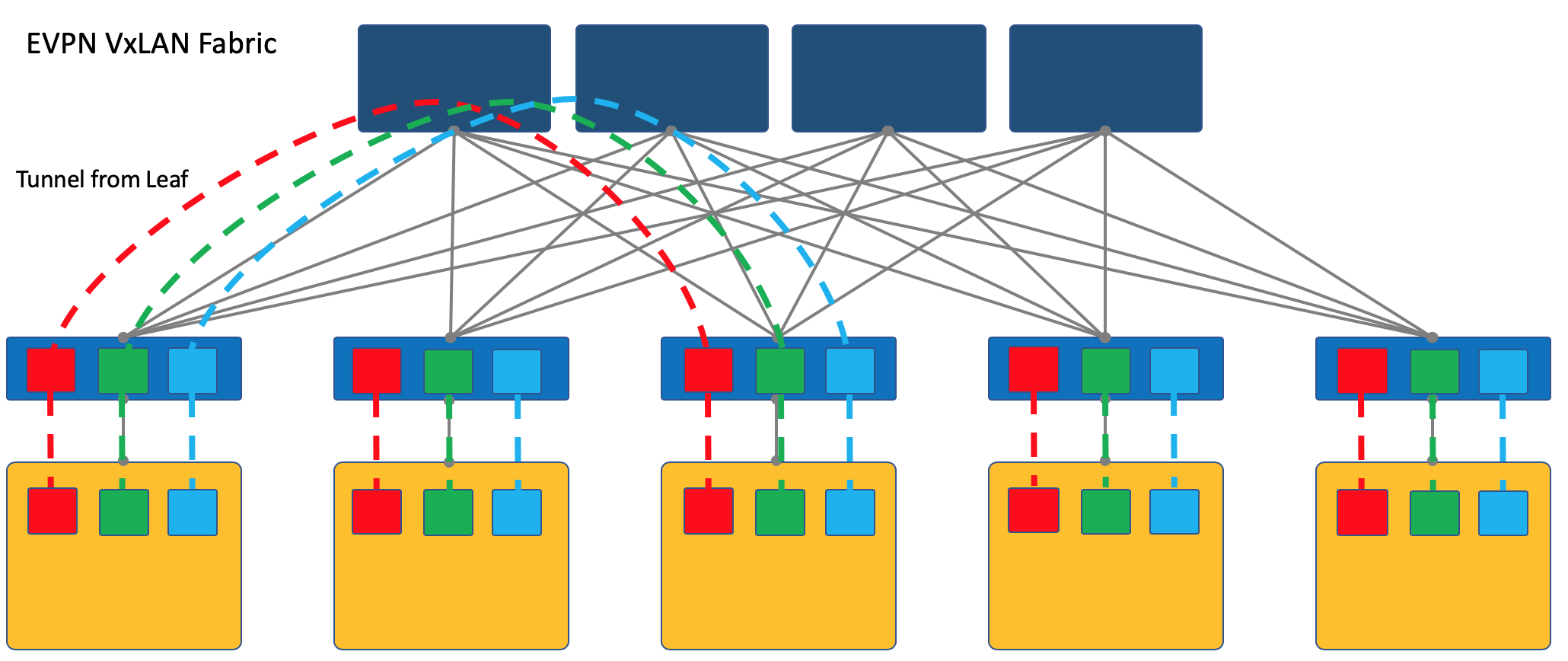
Замечу, что VXLAN - это только метод инкапсуляции и терминация туннелей может происходить не на ToR’е, а на хосте, как это происходит в случае OpenStack’а, например.Однако, VXLAN-фабрика, где overlay начинается на ToR’е является одним из устоявшихся дизайнов оверлейной сети.
Overlay с хоста¶
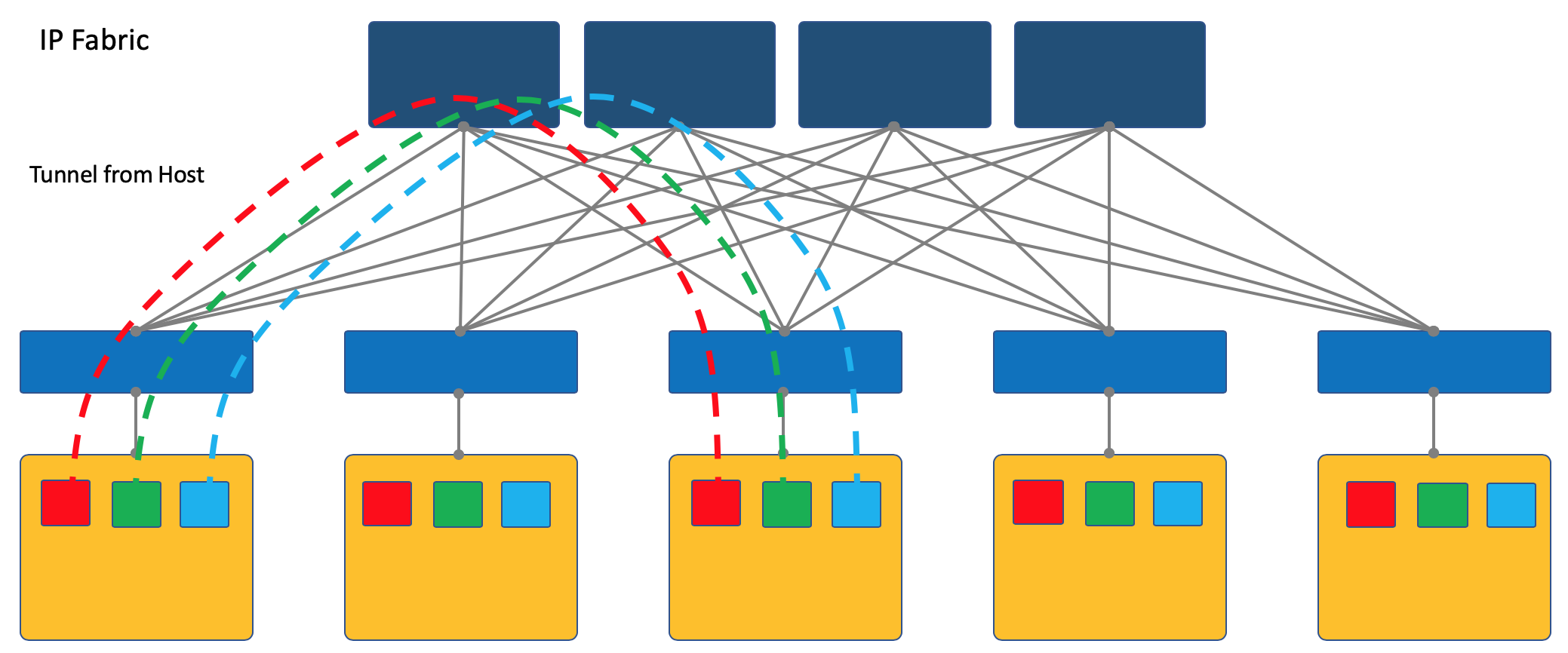
В серии АДСМ я выбираю подход оверлея с хоста - далее мы говорим только о нём и возвращаться к VXLAN-фабрике мы уже не будем.
Проще всего рассмотреть на примерах. И в качестве подопытного мы возьмём OpenSource’ную SDN платформу OpenContrail, ныне известную как Tungsten Fabric.
В конце статьи я приведу некоторые размышления на тему аналогии с OpenFlow и OpenvSwitch.
На примере Tungsten Fabric¶
TAP - Terminal Access Point - виртуальный интерфейс в ядре linux, которые позволяет осуществлять сетевое взаимодействие.
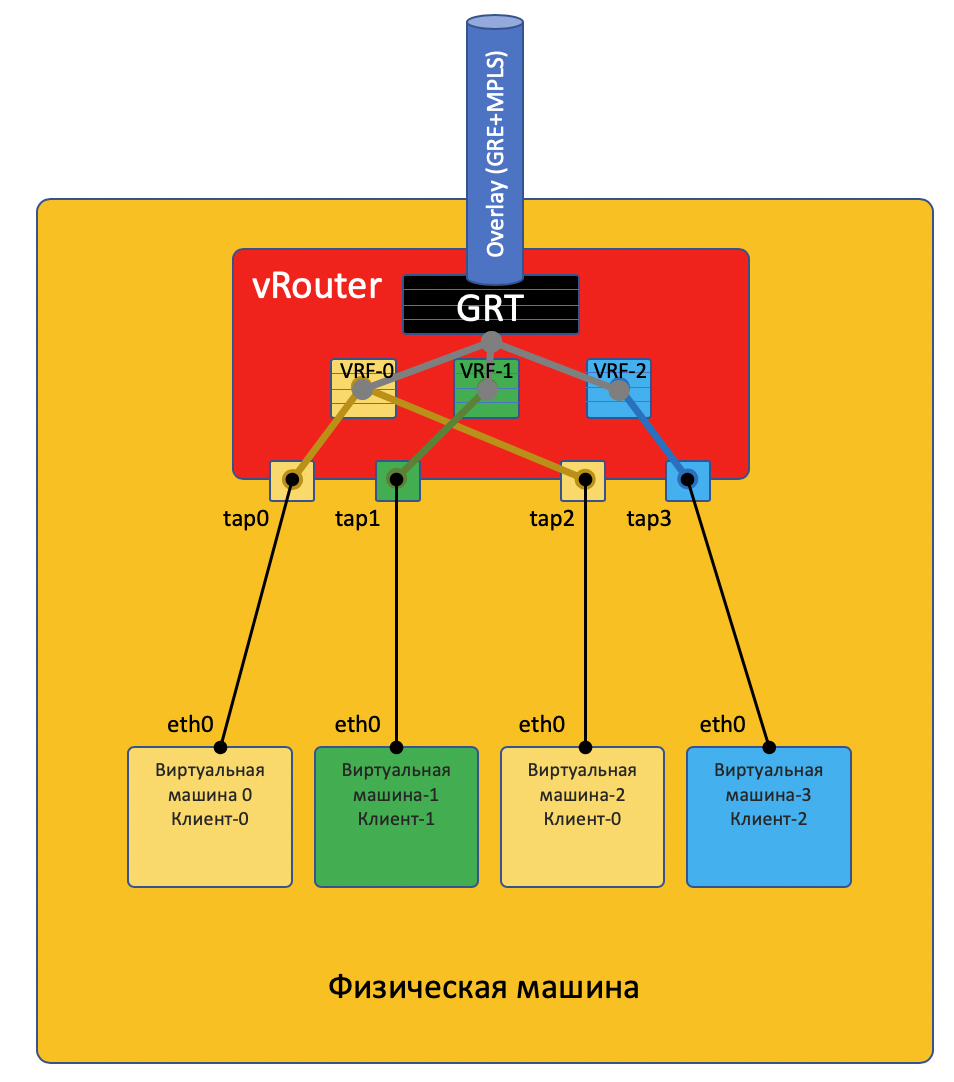
Сделаю тут оговорку, что не всё так просто, и отправлю любознательного читателя в конец статьи.
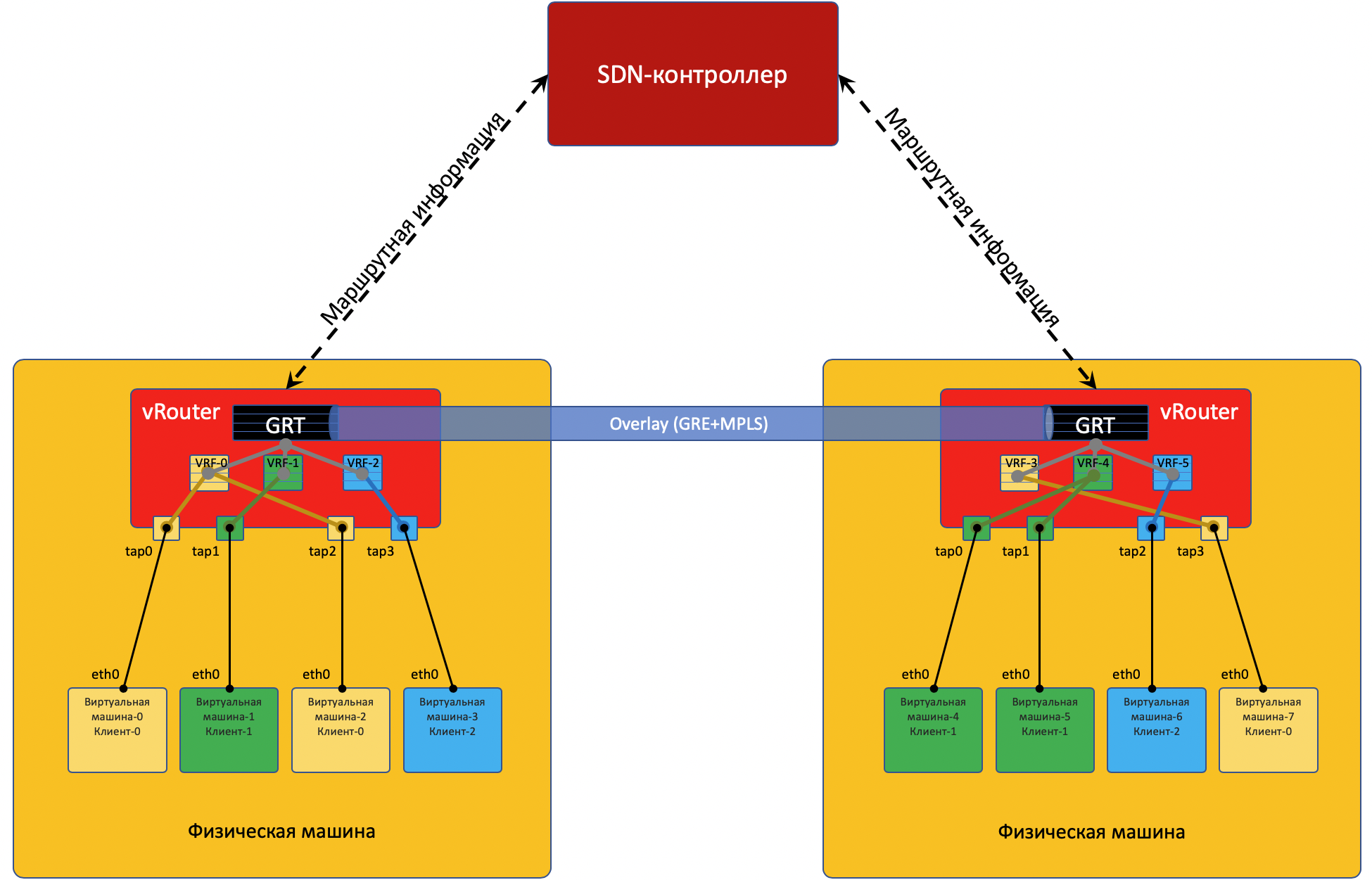
Чтобы vRouter’ы могли общаться друг с другом, а соответственно и ВМ, находящиеся за ними, они обмениваются маршрутной информацией через SDN-контроллер.
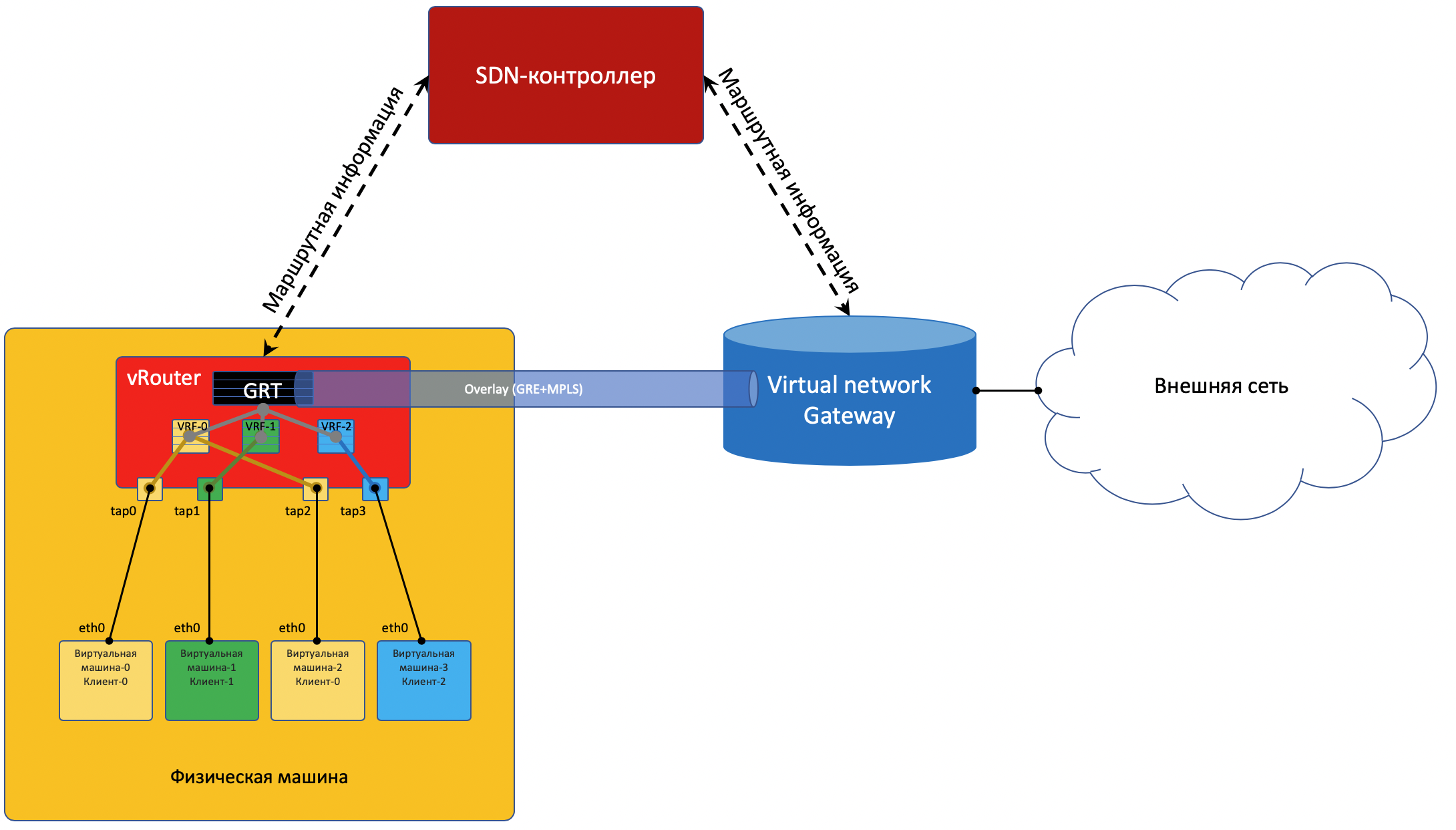
Чтобы выбраться во внешний мир, существует точка выхода из матрицы - шлюз виртуальной сети VNGW - Virtual Network GateWay (термин мой).
Теперь рассмотрим примеры коммуникаций - и будет ясность.
Коммуникация внутри одной физической машины¶
VM0 хочет отправить пакет на VM2. Предположим пока, что это ВМ одного клиента.
Data Plane¶
У VM-0 есть маршрут по умолчанию в его интерфейс eth0. Пакет отправляется туда. Этот интерфейс eth0 на самом деле виртуально соединён с виртуальным маршрутизатором vRouter через TAP-интерфейс tap0.
vRouter анализирует на какой интерфейс пришёл пакет, то есть к какому клиенту (VRF) он относится, сверяет адрес получателя с таблицей маршрутизации этого клиента.
Обнаружив, что получатель на этой же машине за другим портом, vRouter просто отправляет пакет в него без каких-либо дополнительных заголовков - на этот случай на vRouter’е уже есть ARP-запись.
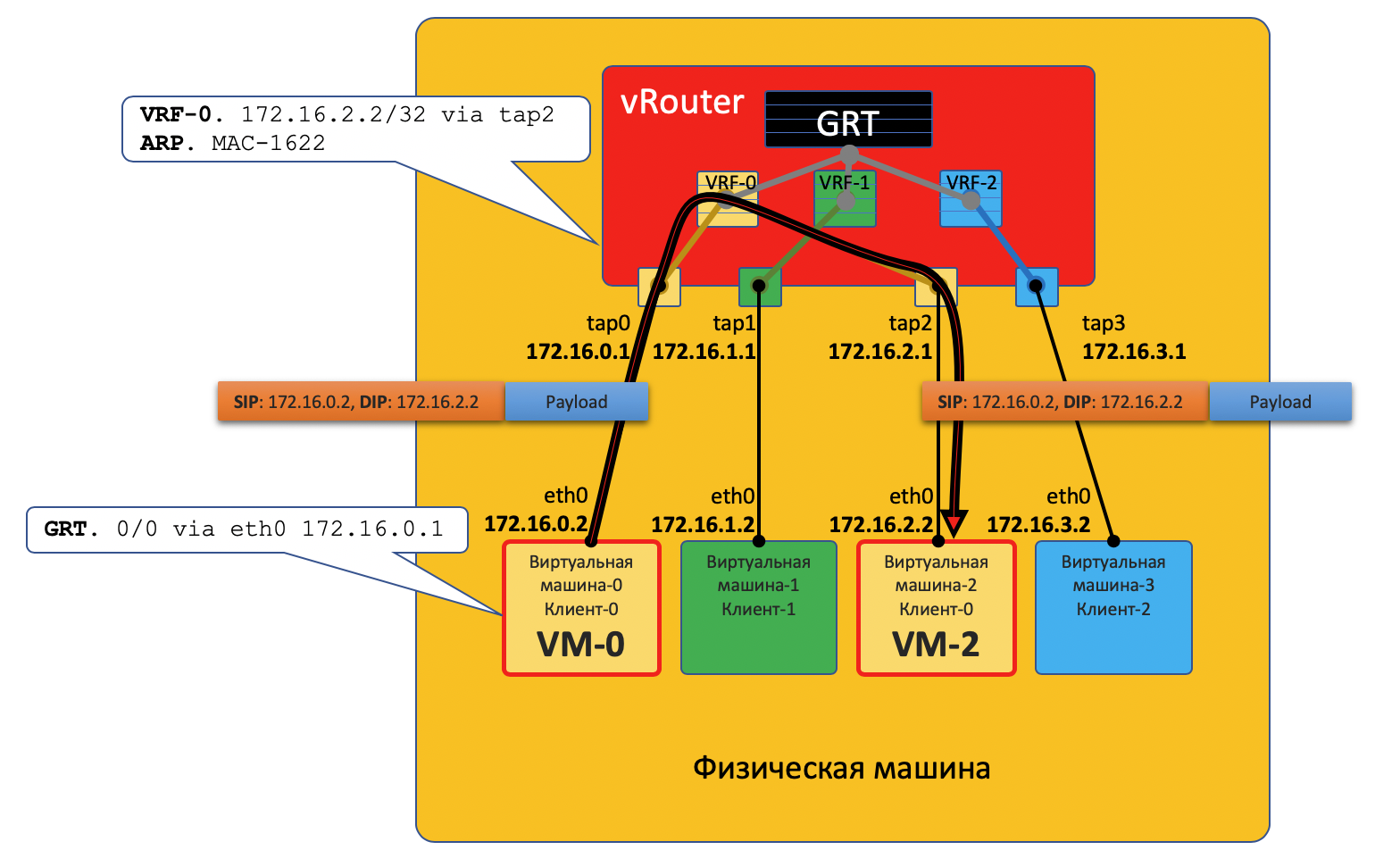
Пакет в этом случае не попадает в физическую сеть - он смаршрутизировался внутри vRouter’а.
Control Plane¶
Гипервизор при запуске виртуальной машины сообщает ей:
- Её собственный IP-адрес.
- Маршрут по умолчанию - через IP-адрес vRouter’а в этой сети.
vRouter’у через специальный API гипервизор сообщает:
Что нужно создать виртуальный интерфейс.
Какой ей (ВМ) нужно создать Virtual Network.
К какому VRF его (VN) привязать.
Статическую ARP-запись для этой VM - за каким интерфейсом находится её IP-адрес и к какому MAC-адресу он привязан.
И снова, реальная процедура взаимодействия упрощена в угоду понимания концепции.
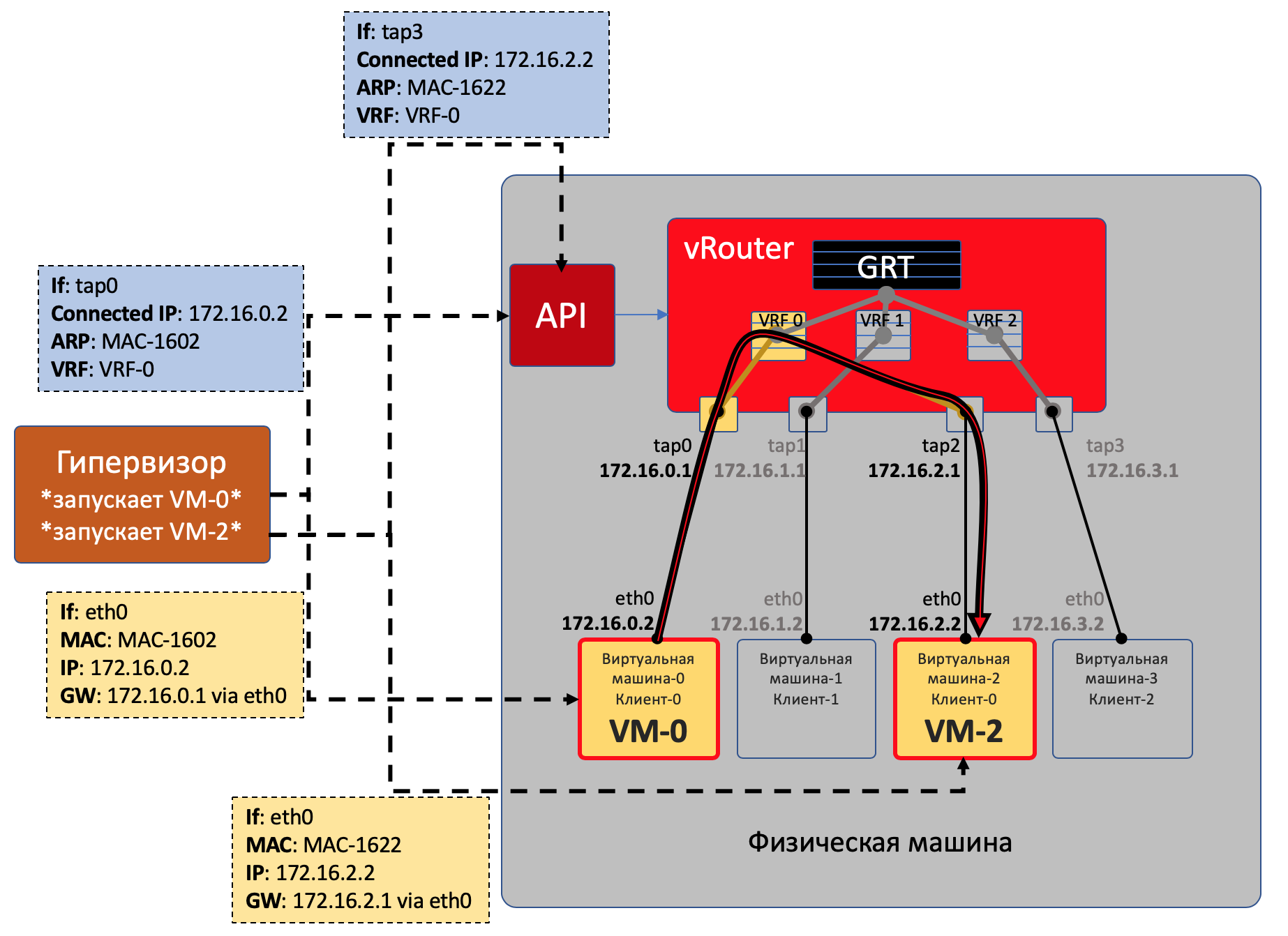
Таким образом все ВМ одного клиента на данной машине vRouter видит как непосредственно подключенные сети и может сам между ними маршрутизировать.
В противной же ситуации возможно пересечение адресных пространств - нужно ходить через NAT-сервер, чтобы получить публичный адрес - это похоже на выход во внешние сети, о которых ниже.
Коммуникация между ВМ, расположенными на разных физических машинах¶
Data Plane¶
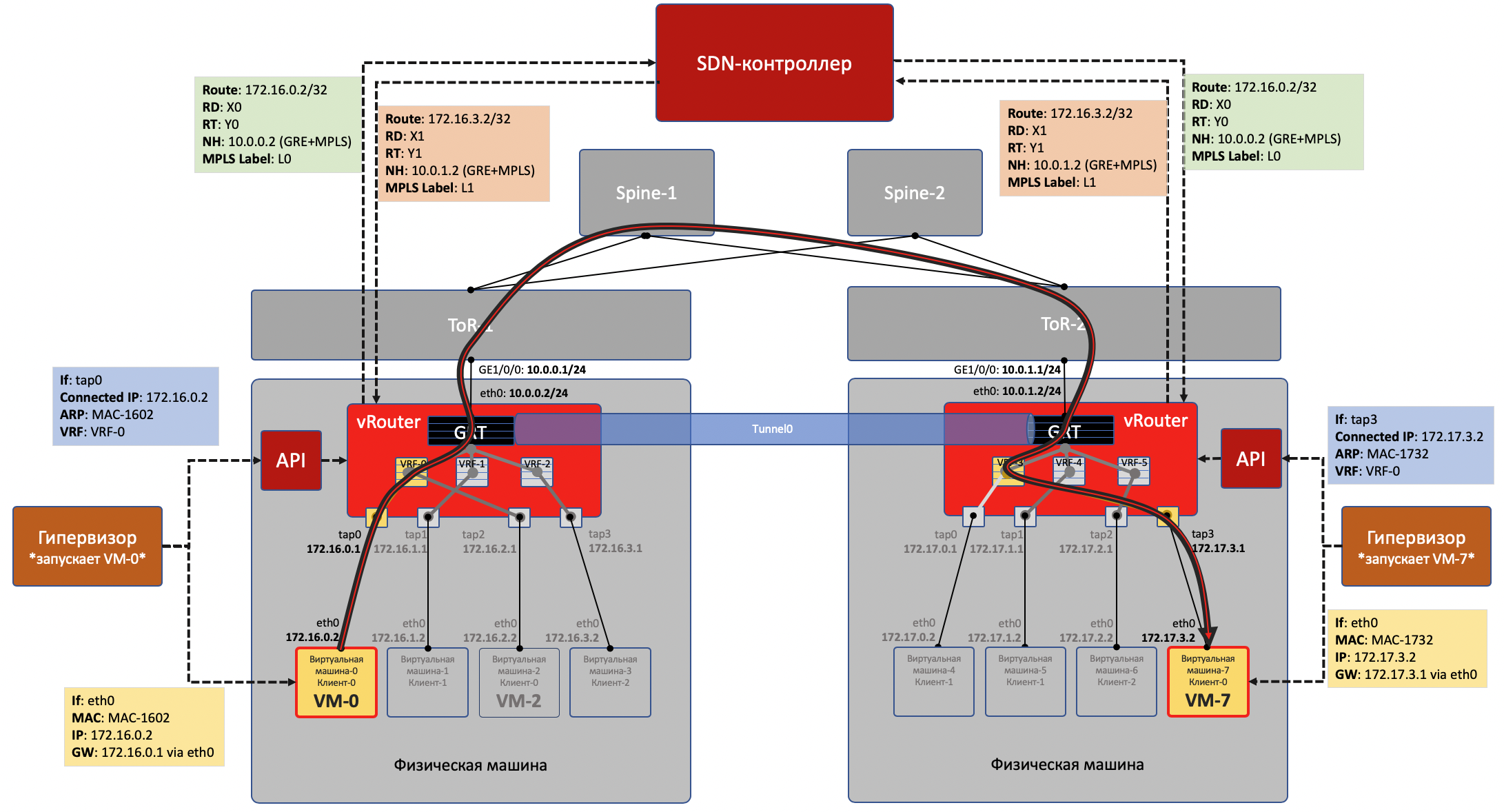
Начало точно такое же: VM-0 посылает пакет с адресатом VM-7 (172.17.3.2) по своему дефолту.
vRouter его получает и на этот раз видит, что адресат находится на другой машине и доступен через туннель Tunnel0.
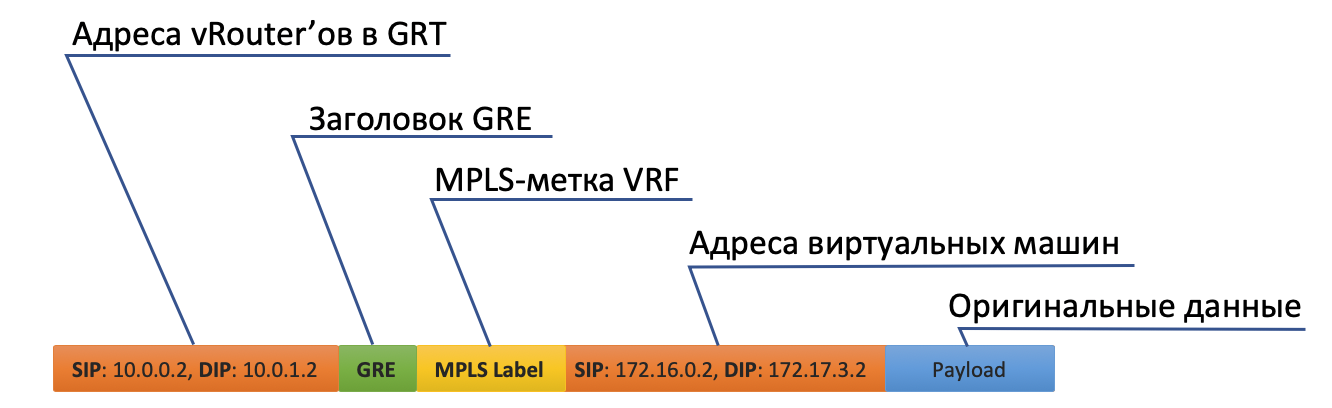
Сначала он вешает метку MPLS, идентифицирующую удалённый интерфейс, чтобы на обратной стороне vRouter мог определить куда этот пакет поместить причём без дополнительных лукапов.

- У Tunnel0 источник 10.0.0.2, получатель: 10.0.1.2.vRouter добавляет заголовки GRE (или UDP) и новый IP к исходному пакету.
В таблице маршрутизации vRouter есть маршрут по умолчанию через адрес ToR1 10.0.0.1. Туда и отправляет.
- ToR1 как участник Underlay сети знает (например, по OSPF), как добраться до 10.0.1.2, и отправляет пакет по маршруту. Обратите внимание, что здесь включается ECMP. На иллюстрации два некстхопа, и разные потоки будут раскладываться в них по хэшу. В случае настоящей фабрики тут будет скорее 4 некстхопа.При этом знать, что находится под внешним заголовком IP ему не нужно. То есть фактически под IP может быть бутерброд из IPv6 over MPLS over Ethernet over MPLS over GRE over over over GREка.
Соответственно на принимающей стороне vRouter снимает GRE и по MPLS-метке понимает, в какой интерфейс этот пакет надо передать, раздевает его и отправляет в первоначальном виде получателю.
Control Plane¶
При запуске машины происходит всё то же, что было описано выше. И плюс ещё следующее:
- Для каждого клиента vRouter выделяет MPLS-метку. Это сервисная метка L3VPN, по которой клиенты будут разделяться в пределах одной физической машины.На самом деле MPLS-метка выделяется vRouter’ом безусловно всегда - ведь неизвестно заранее, что машина будет взаимодействовать только с другими машинам за тем же vRouter’ом и это скорее всего даже не так.
vRouter устанавливает соединение с SDN-контроллером по протоколу BGP (или похожему на него - в случае TF -это XMPP 0_o).
Через эту сессию vRouter сообщает SDN-контроллеру маршруты до подключенных сетей:
- Адрес сети
- Метод инкапсуляции (MPLSoGRE, MPLSoUDP, VXLAN)
- MPLS-метку клиента
- Свой IP-адрес в качестве nexthop
SDN-контроллер получает такие маршруты ото всех подключенных vRouter’ов, и отражает их другим. То есть он выступает Route Reflector’ом.
То же самое происходит и в обратную сторону.
При этом не меняется никоим образом конфигурация Underlay-сети, которую кстати, автоматизировать на порядок сложнее, а сломать неловким движением проще.
Выход во внешний мир¶
Где-то симуляция должна закончиться, и из виртуального мира нужно выйти в реальный. И нужен таксофон^W шлюз.
Практикуют два подхода:
Ставится аппаратный маршрутизатор.
Запускается какой-либо appliance, реализующий функции маршрутизатора (да-да, вслед за SDN мы и с VNF столкнулись). Назовём его виртуальный шлюз.
Преимущество второго подхода в дешёвой горизонтальной масштабируемости - не хватает мощности - запустили ещё одну виртуалку со шлюзом. На любой физической машине, без необходимости искать свободные стойки, юниты, вывода питания, покупать саму железку, везти её, устанавливать, коммутировать, настраивать, а потом ещё и менять в ней сбойные компоненты.Минусы же у виртуального шлюза в том, что единица физического маршрутизатора всё же на порядки мощнее многоядерной виртуалки, а его софт, подогнанный под его же аппаратную основу, работает значительно стабильнее (нет). Сложно отрицать и тот факт, что программно-аппаратный комплекс просто работает, требуя только настройки, в то время как запуск и обслуживание виртуального шлюза - занятие для сильных инженеров.
Одной своей ногой шлюз смотрит в виртуальную сеть Overlay, как обычная Виртуальная Машина, и может взаимодействовать со всеми другими ВМ. При этом она может терминировать на себе сети всех клиентов и, соответственно, осуществлять и маршрутизацию между ними.
Другой ногой шлюз смотрит уже в магистральную сеть и знает о том, как выбраться в Интернет.

Data Plane¶
То есть процесс выглядит так:
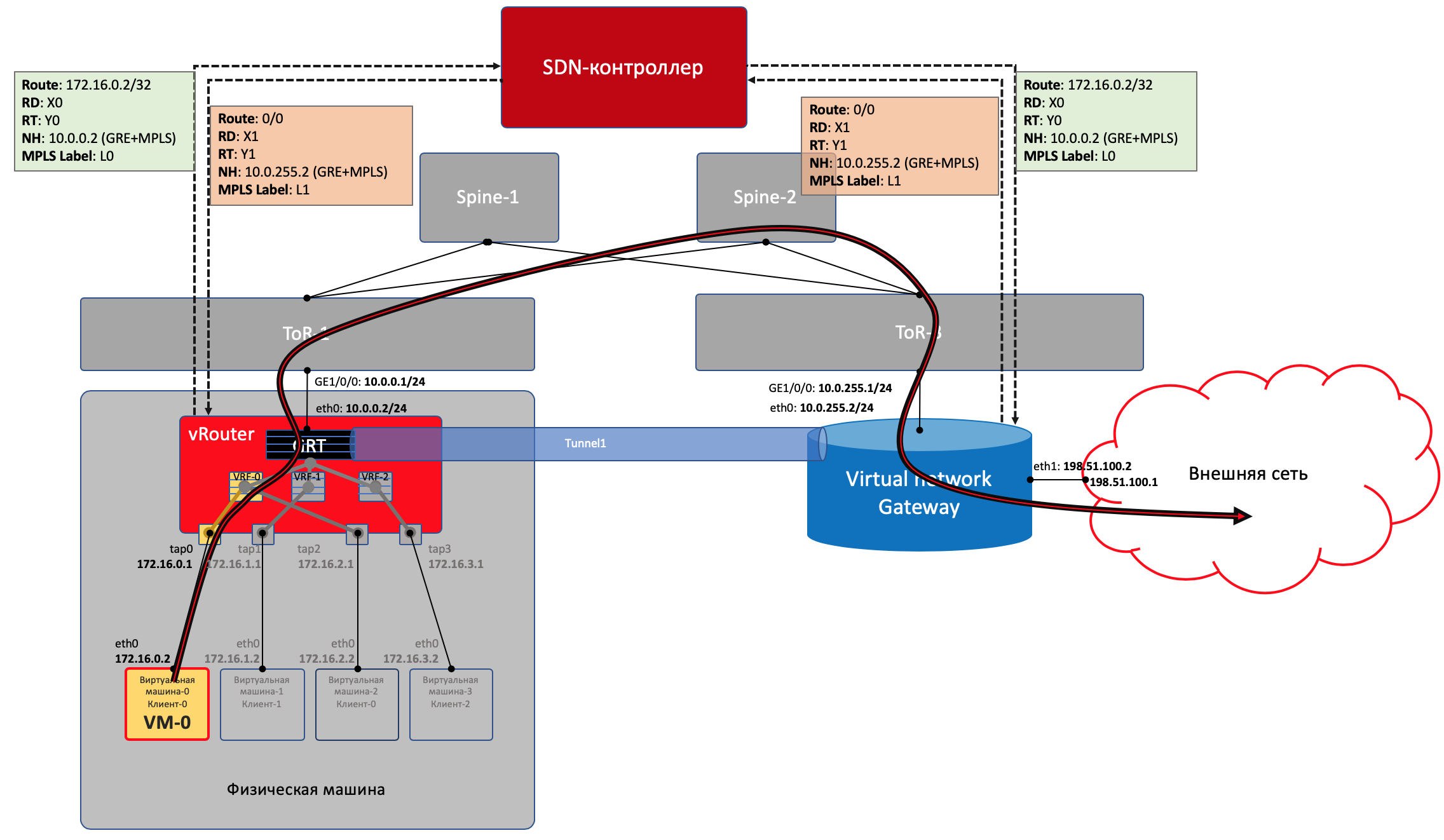
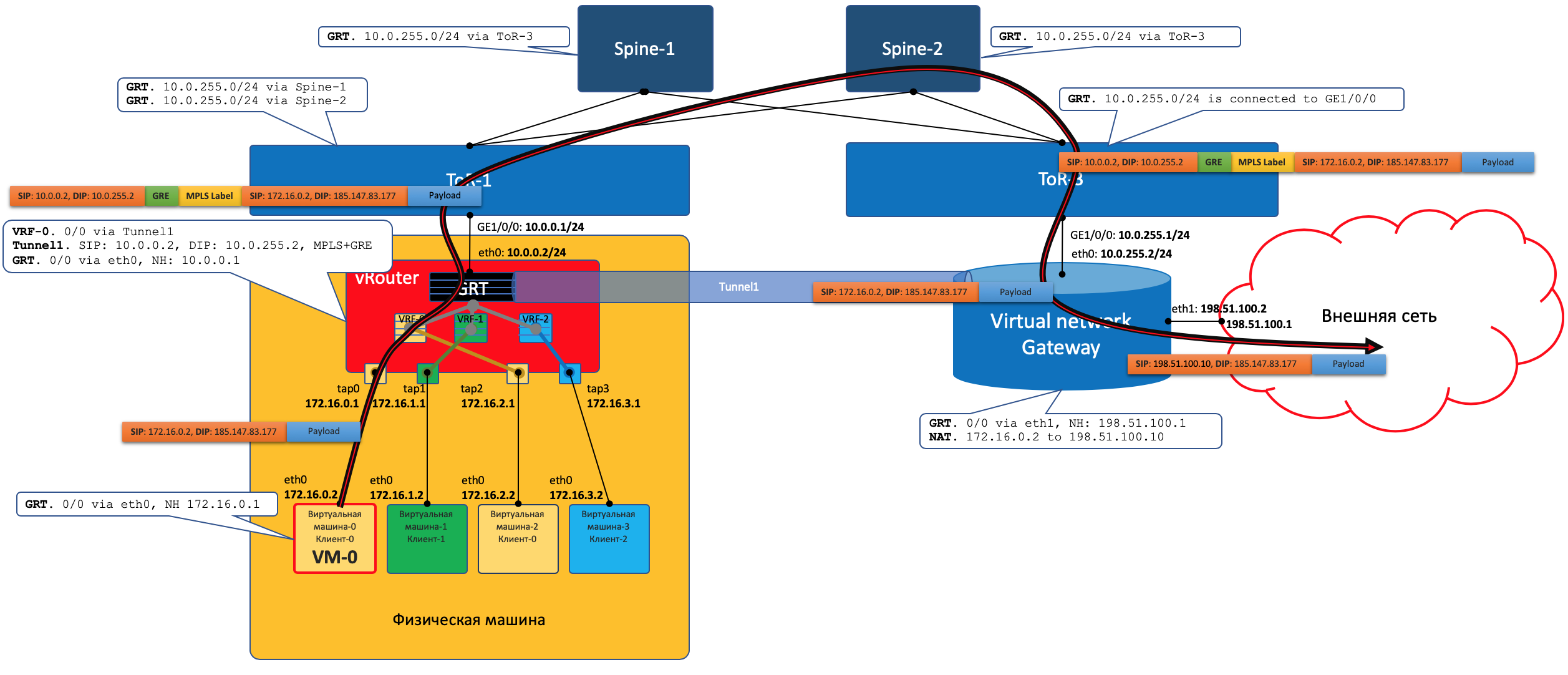
VM-0, имея дефолт всё в тот же vRouter, отправляет пакет с адресатом во внешнем мире (185.147.83.177) в интерфейс eth0.
- vRouter получает этот пакет и делает лукап адреса назначения в таблице маршрутизации - находит маршрут по умолчанию через шлюз VNGW1 через Tunnel 1.Также он видит, что это туннель GRE с SIP 10.0.0.2 и DIP 10.0.255.2, а ещё нужно сначала повесить MPLS-метку данного клиента, которую ожидает VNGW1.
vRouter упаковывает первоначальный пакет в заголовки MPLS, GRE и новый IP и отправляет на адрес ToR1 10.0.0.1 по дефолту.
Андерлейная сеть доставляет пакет до шлюза VNGW1.
Шлюз VNGW1 снимает туннелирующие заголовки GRE и MPLS, видит адрес назначения, консультируется со своей таблицей маршрутизации и понимает, что он направлен в Интернет - значит через Full View или Default. При необходимости производит NAT-трансляцию.
- От VNGW до бордера может быть обычная IP-сеть, что вряд ли.Может быть классическая MPLS сеть (IGP+LDP/RSVP TE), может быть обратно фабрика с BGP LU или GRE-туннель от VNGW до бордера через IP-сеть.Как бы то ни было VNGW1 совершает необходимые инкапсуляции и отправляет первоначальный пакет в сторону бордера.
 Трафик в обратную сторону проходит те же шаги в противоположном порядке.
Трафик в обратную сторону проходит те же шаги в противоположном порядке. Бордер добрасывает пакет до VNGW1
Тот его раздевает, смотрит на адрес получателя и видит, что тот доступен через туннель Tunnel1 (MPLSoGRE или MPLSoUDP).
- Соответственно, вешает метку MPLS, заголовок GRE/UDP и новый IP и отправляет на свой ToR3 10.0.255.1.Адрес назначения туннеля - IP-адрес vRouter’а, за которым стоит целевая ВМ - 10.0.0.2.
Андерлейная сеть доставляет пакет до нужного vRouter’а.
Целевой vRouter снимает GRE/UDP, по MPLS-метке определяет интерфейс и шлёт голый IP-пакет в свой TAP-интерфейс, связанный с eth0 ВМ.

Control Plane¶
VNGW1 устанавливает BGP-соседство с SDN-контроллером, от которого он получает всю маршрутную информацию о клиентах: за каким IP-адресом (vRouter’ом) находится какой клиент, и какой MPLS-меткой он идентифицируется. Аналогично он сам SDN-контроллеру сообщает дефолтный маршрут с меткой этого клиента, указывая себя в качестве nexthop’а. А дальше этот дефолт приезжает на vRouter’ы.