Видимое будущее
Тут на самом деле два направления развития.
Во-первых, совершенно очевидно будут стремительно набирать популярность программные интерфейсы взаимодействия с железом и набивший оскомину на конференциях model-driven programmability.
Рано или поздно он сойдёт со слайдов и начнёт свой путь в каждое домохозяйство.
gNMI слишком хорош, чтобы пройти мимо него. Да и NETCONF, настоенный на YANG’е, тоже.
Будем видеть всё больше статей, больше лаб, разборов. Всё больше вендоров будет нормально поддерживать их и увеличивать покрытие.
Такие требования начнут появляться в RFI.
И это очень-очень-очень хорошо.
Другое направление более интересное и многообещающее.
Whitebox-оборудование. Лет 5 назад это было таким же шумом, как сейчас gNMI. Это - где-то там, у них - у больших и сильных - есть и железо, и софт, и штат R&D для этого интересного.
Сегодня Cumulus, Switchdev, Onos, SONiC - уже вполне зрелые операционные системы, на которых работает прод. Broadcom опубликовал свой SDK на
github - это вообще из разряда «чё творится-то?!»
Почему это важно? И почему эта информация вообще получила место в статье про историю автоматизации?
А всё просто. С появлением Whitebox в мир сетевых операционных систем приходит Linux.
«Да он там и до этого был» - скажут некоторые. Не секрет, что почти все проприетарные сетевые ОС основаны на Linux или FreeBSD. И что с того, если доступа к консоли обычно нет, не говоря уж о руте?
А на Whitebox’ах стоит самый что ни на есть честный Linux, на который можно установить пакеты из репозитория, притащить любой файл, любой бинарник, любой скрипт.
Он превращается в обычный сервер с о-о-очень модными сетевыми карточками с чипом на 12,8 тера.
На нём есть файлы конфигурации, systemd, cron.
А это означает, что обслуживать его можно как обычный Linux-сервер.
Можно поднять nginx и совершенно любое REST-приложение за ним. Ну или gRPC-сервер.
Поставить телеграф-агент - и сливать метрики в коллекторы.
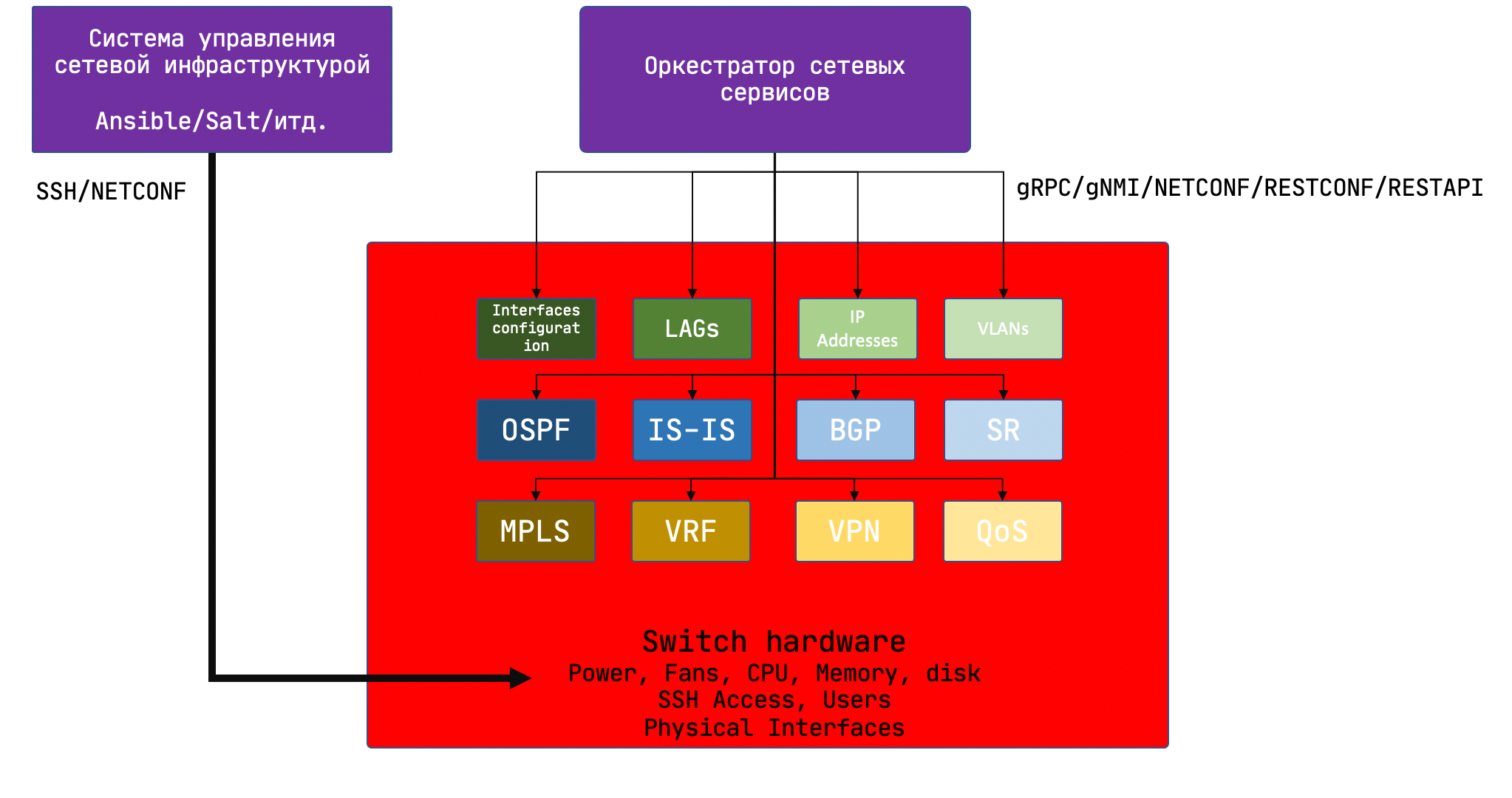
И здесь совершенно чудесно ложится идея разделения управления устройством и сервисами, которые на нём запущены.
Есть Linux-тачка. На ней CPU, память, интерфейсы, пользователи, мониторинги системы и всё такое прочее: но весьма ограниченный набор. Доступ - по SSH. Инструмент - любой, используемый для управления физическими машинами - Ansible, Salt, Chef.
А есть сервисы - BGP, VPN, VxLAN, который на физической машине запущен. И вот они могут управляться через REST, gRPC, ну или хотя бы путём подсовывания конфигурационных файлов.
И менеджмент конфигурации сети становится задачей других, уже существующих отделов: серверной инфраструктуры и config-плейна. Без размазывания компетенций и накладных расходов.
Сетевики всё ещё нужны, очевидно - для определения того, что именно нужно настраивать, как будет выглядеть архитектура сети, набор протоколов, модель данных.
Сюда же можно подтащить версионирование работающих приложений, в которое можно включить и конфигурацию, запуск двух версий side-by-side и где-то не за горизонтом даже полноценный Continious Integation маячит.
А все заморочки с ансиблом, питон-скриптами, притворяющимися человеком с руками и какой-никакой головой, поддержанием стейта конфигурационной портянки текста - они просто испаряются в предрассветном тумане.
И попробуйте после этого взглянуть на существующую модель работы с сетевым железом - какой кривой и инертной она выглядит.
Но есть «Но».
Во-первых, это требует глобальной перестройки всех процессов и вообще-то сознания. Такие вещи за 5 лет не происходят в индустрии - мы ещё долго будем развивать NETCONF.
Во-вторых, это требует всё же некий R&D - в штате должны быть крепкие инфраструктурщики и разработчики. В то время как
идеально вылизанное вендорское железо и софт - требуют весьма ограниченное количество человеческих ресурсов на обслуживание.
В-третьих, это всё сейчас и ещё долгое время будет касаться ДатаЦентров со сравнительно простой сетью, построенной преимущественно на свитчах. В гораздо меньшей степени это применимо к энтерпрайзной сети. А уж когда это докатится до операторов нам будут рассказывать наши внуки. При том что NETCONF там тоже плюс-минус состоялся.
И всё же этот мир прекрасен.
{kind=link}